 SUPPORT
SUPPORT
 3EX United States
3EX United States Blog
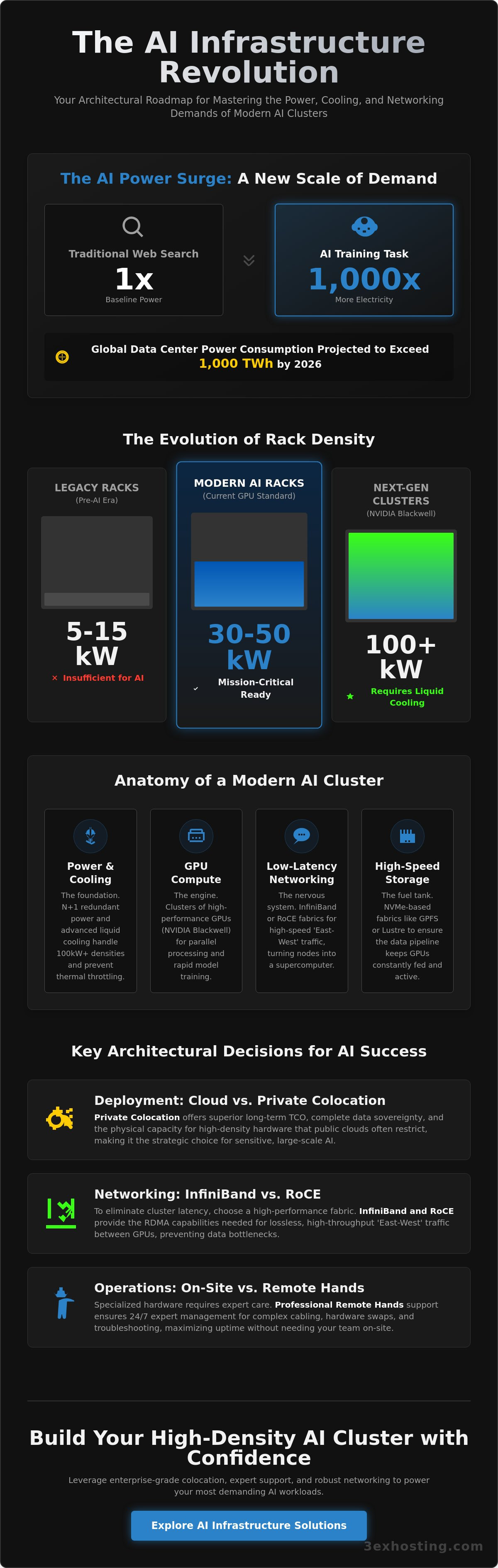
A single AI training task can consume 1,000 times more electricity than a traditional web search. This massive surge is pushing global data center power consumption past 1,000 TWh in 2026. If your team is struggling with legacy racks that can’t handle 30kW+ densities, you’ve reached a common architectural limit. Building the right infrastructure for AI and machine learning clusters requires moving beyond standard data center designs. Traditional air cooling and standard networking fabrics often fail when faced with the compute requirements of NVIDIA Blackwell systems and 100kW rack densities.
Scaling these workloads demands more than just adding more servers. It requires a shift toward liquid cooling and advanced networking like the Ultra Ethernet specification. This guide provides a comprehensive architectural roadmap to master the physical and digital requirements of modern AI. You’ll gain a clear framework for managing power needs, choosing between cloud and colocation, and building a scalable networking architecture that eliminates latency bottlenecks.
Key Takeaways
- Understand why modern AI workloads require up to three times the power of standard data center racks and how to implement N+1 redundancy for mission-critical training.
- Evaluate the total cost of ownership (TCO) to determine when private colocation suites offer better long-term value and data sovereignty than cloud-based alternatives.
- Identify the essential components of infrastructure for AI and machine learning clusters, specifically focusing on the transition from CPU-centric to GPU-accelerated environments.
- Master the complexities of ‘East-West’ traffic by choosing between InfiniBand and RoCE networking architectures to eliminate cluster latency.
- Learn how to maintain high-density hardware through professional remote hands support, ensuring expert cable management and efficient GPU swaps without being on-site.
What is Infrastructure for AI and Machine Learning Clusters?
Modern AI infrastructure isn’t just a collection of servers; it’s an integrated stack where high-density compute, low-latency networking, and specialized cooling work in unison. The industry has moved decisively away from general-purpose CPU compute. Today, GPU-accelerated clusters are the standard for both large-scale training and real-time inference. Building a robust infrastructure for AI and machine learning clusters requires a physical-first approach. This means prioritizing power delivery and thermal management before a single line of code is written.
By 2026, the hardware requirements have reached extreme levels. High-performance GPUs, such as the NVIDIA Blackwell and Hopper architectures, demand massive amounts of energy. These chips can’t operate at peak performance without InfiniBand networking to eliminate communication bottlenecks and NVMe storage to keep the data pipeline full. Many enterprises now find that private colocation suites offer the best balance of cost and data sovereignty. This shift allows teams to maintain total control over their sensitive training data while leveraging the high-density power that standard offices or legacy data centers can’t provide.
The Evolution of AI Compute Density
Data center requirements have changed rapidly. Only a few years ago, a 5kW rack was the enterprise standard. Today, AI-ready cabinets frequently exceed 50kW, with some Blackwell-based systems pushing toward 100kW. Standard enterprise data centers are often ill-equipped for these ML clusters because their cooling systems can’t dissipate the concentrated heat. This gap has made specialized AI infrastructure hosting essential. It provides the liquid cooling and power redundancy necessary to prevent hardware throttling during intense training runs.
Core Components of a Modern AI Stack
A functional AI cluster relies on several critical hardware layers. GPU dedicated servers act as the primary engines of the operation. To prevent these engines from idling, you need high-speed storage fabrics like GPFS or Lustre. These systems ensure that data moves from storage to GPU memory at lightning speed. It’s also vital to distinguish between the ‘Node’ and the ‘Cluster.’ A node is a single server unit, while the cluster is the interconnected whole. In an infrastructure for AI and machine learning clusters, the networking fabric is what turns separate nodes into a singular, powerful supercomputer. Without this high-speed interconnect, your GPUs will spend more time waiting for data than processing it.
Power and Cooling: Solving the High-Density AI Challenge
AI training creates a “Power Gap” that most legacy facilities can’t bridge. Standard enterprise workloads typically draw 5 to 15 kW per rack. In contrast, a modern infrastructure for AI and machine learning clusters often requires 30 kW to 100 kW per cabinet. This massive increase in power density isn’t just a capacity issue; it’s a stability challenge. High-density GPU clusters pull massive amounts of current during peak training phases, requiring electrical systems that can handle sudden, intense spikes without failing.
Implementing N+1 power redundancy is mandatory for these mission-critical runs. A single power failure can corrupt a training checkpoint. This leads to weeks of lost progress and wasted compute spend. By distributing loads across independent power paths, you ensure that your cluster remains operational even if a primary feed or UPS fails. Efficiently managing these loads is the only way to maintain a low Power Usage Effectiveness (PUE) in high-density environments. Lower PUE ratings aren’t just about sustainability; they directly impact the total cost of ownership for your AI project.
Rack-Level Power Management
Precision at the rack level starts with intelligent Power Distribution Units (PDUs). Metered power is a critical tool for AI cost tracking in 2026. These units allow teams to monitor real-time consumption and identify underperforming nodes before they fail. When utilizing full cabinet colocation, balancing these loads is essential to prevent hot spots. Distributing high-draw servers across multiple circuits prevents circuit breaker trips during high-intensity inference or training cycles.
Advanced Cooling for GPU Clusters
Air cooling alone is no longer sufficient for the 2026 hardware landscape. While Rear-door heat exchangers (RDHx) provide a bridge for moderately dense setups, the industry is transitioning rapidly to liquid-to-chip cooling. Direct-to-chip solutions remove heat more effectively than air. This allows GPUs to run at higher clock speeds without thermal throttling. This is particularly vital for systems like the NVIDIA Blackwell GB300 NVL72, which are designed as liquid-cooled units from the factory. 3EX Hosting optimizes high density colocation by integrating these advanced thermal management strategies into the facility’s core design. This ensure that your hardware stays within safe operating temperatures, regardless of the workload intensity.
Comparing Deployment Models: AI Cloud vs. Private Colocation
Choosing the right deployment model is a pivotal decision for any enterprise scaling its infrastructure for AI and machine learning clusters. While public cloud providers offer immediate access to the latest GPUs, the long-term financial and operational costs often tell a different story. A 2025 report indicated that 74% of organizations prefer a hybrid cloud approach for AI infrastructure. This shift suggests that the most effective strategy isn’t choosing one over the other. Instead, it involves placing workloads where they are most efficient. Training large-scale models requires consistent, heavy compute power that can make cloud-only models prohibitively expensive over time.
Latency and performance also play a major role in this comparison. In a private colocation environment, you have total control over dedicated physical interconnects. This eliminates the “noisy neighbor” effect common in shared cloud environments. Dedicated networking ensures that data moves between nodes at the full speed of your hardware, which is essential for the synchronous nature of deep learning. When your GPUs aren’t waiting for the network, your training times drop and your hardware ROI increases. Many enterprises now use a hybrid model: they perform heavy training in a colocation facility and use the cloud for burst inference and global distribution.
The ROI of Private AI Infrastructure
Calculating the total cost of ownership (TCO) requires looking past the initial hardware purchase. While the capital expenditure (CAPEX) for GPU clusters is high, the ongoing operational savings are significant. You avoid the “Cloud Tax,” which includes aggressive markups on data egress and high-performance storage. For persistent workloads, owning the hardware and utilizing Full Cabinet Colocation often results in a lower cost per teraflop. Learn more about Full Cabinet Colocation for AI to see how fixed costs can stabilize your long-term research budget.
Security and Compliance in AI Training
Data sovereignty is a non-negotiable requirement for many organizations. Training proprietary models on sensitive datasets requires absolute control over the physical and digital environment. Private colocation suites provide a level of isolation that shared cloud environments can’t match. This is especially critical for meeting strict compliance standards like SOC2 or HIPAA. Utilizing a cage solutions datacenter ensures that your hardware is physically segregated. This physical security, combined with custom encryption protocols, provides a secure foundation for your most valuable intellectual property.
Networking Architecture for Machine Learning Clusters
Standard enterprise networks are typically designed to handle “North-South” traffic, where users interact with applications. AI clusters flip this requirement entirely. They rely on massive “East-West” traffic, where servers communicate with each other at lightning speeds. In a robust infrastructure for AI and machine learning clusters, the networking fabric is the nervous system that synchronizes thousands of GPU cores. If the network introduces even a microsecond of unexpected latency, the entire cluster idles. This is known as the “tail latency” problem; the slowest link in your network dictates the speed of your entire training job.
Architects in 2026 must choose between InfiniBand and RDMA over Converged Ethernet (RoCE). InfiniBand has long been the gold standard for its lossless nature and low overhead. However, the emergence of the Ultra Ethernet Consortium (UEC) specification v1.0.2 in early 2026 has made Ethernet a formidable competitor. These technologies allow for Remote Direct Memory Access (RDMA), which lets GPUs pull data directly from the memory of another node without involving the CPU. This bypass significantly reduces the processing load and keeps the data pipeline moving at peak capacity.
Building the Interconnect Fabric
A non-blocking fabric design is essential to prevent congestion during all-reduce operations. This requires a leaf-spine architecture where every leaf switch connects to every spine switch, providing predictable, low-latency paths. For those scaling across multiple cabinets, High-Density GPU Colocation provides the physical foundation for these complex interconnects. You can explore more about these specific requirements in our guide on High-Density GPU Colocation: The Enterprise Guide to AI Infrastructure in 2026.
Carrier Neutrality and AI Connectivity
Physical proximity to diverse data sources is a strategic advantage. Operating within a carrier-neutral facility allows you to access multiple fiber providers and Tier-1 carriers. This diversity ensures that your infrastructure for AI and machine learning clusters can ingest massive datasets from various geographical locations without bottlenecks. By utilizing Cross-Connect Services, you can establish direct, private links to cloud providers or data lakes. This redundancy in the physical networking layer prevents single points of failure and optimizes the path for global application delivery. To ensure your cluster has the lowest possible latency to external data, request a quote for our Cross-Connect Services today.
Operational Excellence: Managing Your AI Cluster
Building a robust infrastructure for AI and machine learning clusters is only the first step. The ongoing management of these high-performance systems presents a unique set of challenges, particularly when the hardware is located in a remote facility. High-density GPU servers are sensitive to environmental changes and require precise physical handling. You can’t simply treat a liquid-cooled rack like a standard web server. Operational excellence in this field means having a strategy for hardware maintenance that doesn’t require your primary engineering team to be on-site for every minor adjustment.
Future-proofing your deployment is equally important. As your models grow in complexity, your physical footprint must be able to expand without disrupting existing operations. Modular cage solutions allow for this growth by providing a secure, dedicated space that can be built out in phases. This approach ensures that you don’t overpay for space today while maintaining the ability to scale to a full private suite as your compute requirements increase. Designing for modularity from day one prevents the need for costly and risky hardware migrations later.
The Role of Remote Hands in AI
Reliable 24/7 technical support is the backbone of remote cluster management. When a GPU fails or a network cable becomes unseated during an intense training run, you need immediate intervention. Professional remote hands teams are trained to handle the specific requirements of high-density hardware, from performing delicate GPU swaps to managing the complex fiber-optic cabling required for InfiniBand fabrics. Remote hands support significantly reduces the Mean Time to Repair (MTTR) for AI clusters by providing on-site experts who can execute physical tasks within minutes of a ticket being opened. This level of responsiveness is vital for maintaining the high availability required for competitive AI development. You can Explore 3EX Hosting Remote Hands Support to see how our team manages these critical environments.
Strategic Growth and Disaster Recovery
Disaster recovery for AI isn’t just about data backups; it’s about protecting your training progress. Losing a week of compute time on a large-scale model can cost an enterprise thousands of dollars in wasted electricity and hardware wear. Implementing disaster recovery solutions specifically for AI involves frequent checkpointing and off-site storage of model weights. This ensures that even in the event of a catastrophic hardware failure, your team can resume training from the last known good state with minimal delay. As you scale from a single cabinet to private colocation suites, these protocols become even more essential for protecting your intellectual property. If you’re ready to secure your hardware’s future, the next step is to Get a Quote for Your AI Infrastructure and build a roadmap for scalable, resilient growth.
Future-Proofing Your AI Roadmap
Mastering the infrastructure for AI and machine learning clusters is no longer just a software challenge. It’s a physical reality that demands high-density power management and advanced thermal solutions. By prioritizing liquid cooling and low-latency networking fabrics like InfiniBand or RoCE, you ensure your GPUs spend their time processing data rather than waiting for the network. Choosing a private colocation model over a purely cloud-based approach provides the cost stability and data sovereignty needed for long-term research success.
Success in 2026 requires a partner that understands these technical nuances. We provide the stability of N+1 power redundancy and the flexibility of carrier-neutral connectivity to keep your training runs operational. With 24/7 remote hands support, your hardware is always in expert hands, regardless of your physical location. It’s time to move from experimental setups to a professional, scalable foundation that can handle the most demanding workloads of the next decade.
Build your high-density AI infrastructure with 3EX Hosting and take control of your computational future today.
Frequently Asked Questions
What is the minimum power density required for an AI cluster?
Minimum power density for an infrastructure for AI and machine learning clusters starts at 30kW per rack. While traditional data centers operate at 5 to 15kW, modern GPU clusters require significantly more energy to prevent thermal throttling. By 2026, many specialized facilities are designing for densities exceeding 100kW to accommodate the latest NVIDIA Blackwell systems. Ensuring your facility can provide this level of power is the first step in successful cluster deployment.
Is liquid cooling mandatory for NVIDIA Blackwell GPU hosting in 2026?
Liquid cooling is essentially mandatory for the NVIDIA Blackwell platform in 2026. Systems like the GB300 NVL72 are designed as liquid cooled, rack scale units from the factory because air cooling can’t dissipate heat from 100kW racks. Direct to chip or rear door heat exchangers are now standard requirements. Without these advanced thermal management strategies, your high performance hardware will automatically downclock to protect itself, severely impacting your training timelines.
How do I choose between InfiniBand and Ethernet for my ML cluster?
Choosing between InfiniBand and Ethernet depends on your existing ecosystem and performance requirements. InfiniBand remains the gold standard for lossless, low latency communication in large scale training. However, Ethernet has closed the gap with the Ultra Ethernet Consortium (UEC) v1.0.2 specification released in early 2026. If you prioritize interoperability and have existing Ethernet expertise, RoCEv2 is a viable alternative. Most enterprises choose InfiniBand for the most demanding training runs.
Can I use standard colocation for high-density GPU servers?
Standard colocation is generally insufficient for a modern infrastructure for AI and machine learning clusters. Most general purpose data centers can’t support the 30kW draws or the specialized liquid cooling infrastructure these servers require. High density GPU hosting requires a facility designed with reinforced floors, advanced power redundancy, and high capacity cooling loops. Attempting to use standard racks often leads to frequent circuit trips and hardware overheating during intense compute cycles.
What are the security benefits of private colocation suites for AI training?
Private colocation suites offer physical isolation and absolute control over your training environment. Unlike shared cloud environments, private suites ensure that your proprietary models and sensitive datasets reside on dedicated hardware within a locked cage. This setup is critical for meeting SOC2 or HIPAA compliance standards. It also eliminates the risk of side channel attacks or data leakage that can occur in multi tenant cloud architectures where hardware is shared.
How does remote hands support help in managing an AI cluster?
Remote hands support acts as your on-site engineering team for physical hardware tasks. These technicians handle delicate GPU swaps, InfiniBand cable management, and power cycling without requiring your team to travel. In an AI context, this support is vital for reducing Mean Time to Repair (MTTR). Fast intervention ensures that a single component failure doesn’t stall a training job that might be costing thousands of dollars in compute time every hour.
What is the impact of network latency on AI model training speed?
Network latency is a primary bottleneck that can cause expensive GPUs to sit idle. During the “all-reduce” phase of model training, nodes must synchronize their gradients across the entire cluster. Even microsecond delays, often called “tail latency,” force the fastest GPUs to wait for the slowest network link. This synchronization overhead can reduce your overall training efficiency by 20% or more if your networking fabric isn’t properly optimized for high speed communication.
How can I calculate the TCO of private AI infrastructure vs. cloud?
To calculate TCO, you must weigh the upfront capital expenditure of hardware against the ongoing “cloud tax” of egress and high performance storage. While cloud instances offer low entry costs, the cumulative monthly fees and data movement charges often exceed the cost of owning hardware within 18 to 24 months. For persistent, high utilization training workloads, private colocation typically provides a much lower cost per teraflop over the hardware’s three year lifecycle.