 SUPPORT
SUPPORT
 3EX United States
3EX United States Blog
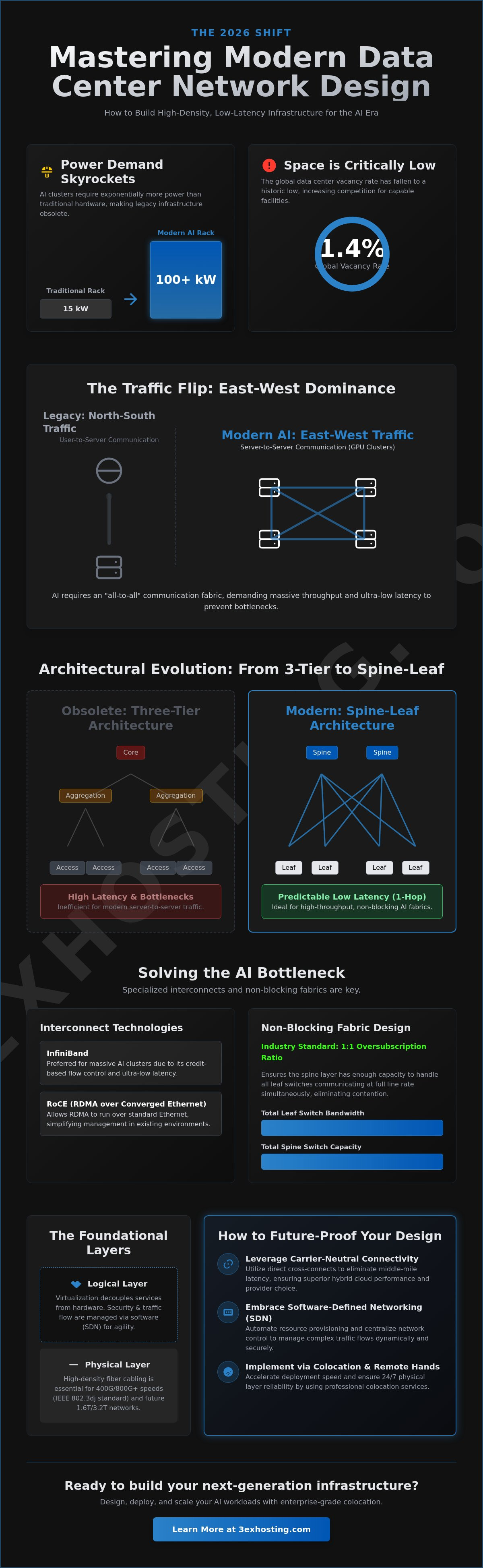
In 2026, the global data center vacancy rate has fallen to a record-low 1.4%, yet power demands are skyrocketing. Traditional racks once pulled 15 kW, but modern AI clusters now require over 100 kW per rack. This shift makes legacy data center network infrastructure design obsolete almost overnight. You’re likely facing the reality that yesterday’s cabling and cooling simply can’t support the 800G networking speeds required for today’s workloads.
It’s frustrating to manage the complexity of hybrid cloud interconnections while proprietary hardware costs continue to climb. We understand that technical stability and speed are your top priorities. This guide shows you how to master modern network design principles to build a high-density, low-latency infrastructure. You’ll learn to leverage carrier-neutral connectivity and the latest IEEE 802.3dj standards to future-proof your architecture. We’re moving beyond simple server connections to create a robust interconnectivity fabric that handles AI-driven data surges with ease.
Key Takeaways
- Understand the shift toward East-West traffic dominance and how it redefines modern server-to-server communication patterns.
- Master the core principles of data center network infrastructure design to build a fabric capable of supporting high-density GPU clusters and AI model training.
- Learn how carrier-neutral environments and direct cross-connect services eliminate middle-mile latency for superior hybrid cloud performance.
- Explore the role of Software-Defined Networking (SDN) in automating resource provisioning and centralizing control across complex enterprise architectures.
- Discover how colocation and professional remote hands support can accelerate your deployment speed while ensuring 24/7 physical layer reliability.
Core Principles of Modern Data Center Network Infrastructure Design
Modern data center network infrastructure design has moved beyond simply connecting racks to a central core. It’s now a unified integration of physical hardware and logical software layers. In 2026, the primary driver for this shift is the explosion of AI and machine learning workloads. These processes have flipped traffic patterns on their head. Instead of traffic moving primarily between users and servers (North-South), the vast majority now moves between servers within the cluster (East-West). This change requires an architecture that prioritizes massive throughput and ultra-low latency to prevent bottlenecks during intense model training cycles.
Designing for modularity is the most critical factor for enterprise scaling in this environment. A modular approach allows you to add capacity in predictable increments without redesigning the entire fabric. By 2026, design goals have crystallized around automated provisioning and 800G readiness. Systems must be able to allocate bandwidth dynamically as GPU clusters demand more resources. This flexibility ensures that your data center network infrastructure design remains relevant as networking speeds migrate toward the 1.6T and 3.2T thresholds expected in the coming years.
Logical vs. Physical Network Layers
The physical layer is the foundation. It requires high-density fiber cabling to support the IEEE 802.3dj standard. While copper still has its place for short-range connections, fiber is essential for the 400G and 800G speeds defining modern clusters. The logical layer sits above this, using virtualization to decouple network services from the physical hardware constraints. This separation allows you to manage security policies and traffic flow through software. It makes the network more agile and significantly easier to secure against evolving threats without manual hardware intervention.
Topologies: From Three-Tier to Spine-Leaf
The traditional Three-Tier model, consisting of core, aggregation, and access layers, is becoming obsolete for AI-centric facilities. It introduces too much latency for modern server-to-server communication. Most engineers now favor Spine-Leaf architecture because it ensures every leaf switch is exactly one hop away from every other leaf. This creates predictable, non-blocking performance. For specialized high-performance computing (HPC) environments, designers often look toward data center network architectures like Fat Tree or Clos networks. These topologies provide the massive bandwidth and redundancy needed for the all-to-all communication patterns inherent in large-scale AI training.
Designing for High-Density AI and GPU Workloads
AI model training creates a unique stress test for any data center network infrastructure design. Unlike standard enterprise applications, AI workloads rely on “all-to-all” communication patterns. This means every GPU in a cluster must exchange data with every other GPU simultaneously. If the network cannot handle this bursty, high-volume traffic, the expensive compute resources sit idle. Efficiently managing these patterns requires a move away from traditional Ethernet toward specialized interconnects like InfiniBand or RoCE (RDMA over Converged Ethernet).
InfiniBand is often the preferred choice for massive AI clusters because of its credit-based flow control and ultra-low latency. However, RoCE has gained significant traction by allowing RDMA to run over standard Ethernet fabrics. This simplifies the management of high density GPU colocation environments where existing Ethernet expertise is already in place. As these fabrics grow in complexity, the role of Software-Defined Networking (SDN) becomes vital for managing the dynamic traffic flows of multi-tenant GPU environments. Selecting the right interconnect is the first step in avoiding the “AI bottleneck” that can stall productivity.
Solving the AI Bottleneck: Non-Blocking Fabrics
A non-blocking fabric ensures that any node can communicate with any other node at full line rate without contention. In 2026, the industry standard for AI training fabrics has shifted to a 1:1 oversubscription ratio. This means the total bandwidth available at the leaf switches matches the capacity of the spine switches. Tail latency is the delay experienced by the slowest packets in a data transfer; it is a critical metric because a single delayed packet can force thousands of GPUs to wait before starting the next training iteration.
Infrastructure Density and Rack Design
High-density networking brings significant physical challenges. When utilizing full cabinet colocation, you must account for the immense heat generated by both the GPUs and the high-speed 800G switches. Modern designs often integrate liquid cooling manifolds directly into the rack layout to handle densities exceeding 40 kW. Cable management is equally critical. High-count fiber deployments using MPO/MTP connectors require precise routing to maintain airflow and prevent signal degradation. If you’re struggling with the physical complexity of these setups, our remote hands support can assist with the intricate layer-one maintenance required for high-performance clusters.
The Connectivity Layer: Cross-Connects and Carrier Neutrality
A resilient data center network infrastructure design isn’t complete without a robust strategy for external connectivity. While internal spine-leaf fabrics handle the heavy lifting of AI processing, the connectivity layer determines how effectively your data reaches the outside world. Carrier-neutral facilities provide the ultimate advantage here. They don’t tie you to a single provider’s pricing or performance limitations. Instead, they act as a marketplace where you can select the best Tier-1 carriers for your specific latency and geographic requirements. This flexibility is the bedrock of technical stability in a fluctuating market.
Speed is often won or lost in the “middle mile.” By utilizing cross-connect services, you bypass the public internet entirely. These direct physical connections between your equipment and a carrier’s Point of Presence (PoP) eliminate multiple hops, slashing latency to sub-millisecond levels. For hybrid cloud architectures, integrating Cloud On-Ramps is equally vital. These dedicated links to hyperscalers like AWS or Azure ensure that your private infrastructure and public cloud resources function as a single, low-latency environment. To maintain 100% uptime, we recommend a multi-homed BGP configuration. This protocol automatically reroutes traffic if one carrier fails, ensuring your services remain reachable without manual intervention.
Direct Interconnections vs. Public Internet
Security is the most compelling reason to favor direct interconnections over the public internet. Private links significantly reduce the attack surface for DDoS and man-in-the-middle attacks because your data never touches the open web. From a performance standpoint, the difference is stark. Public routes are unpredictable and subject to congestion. Physical cross-connects provide consistent, guaranteed throughput. While peering at an Internet Exchange (IX) requires an initial investment, the cost-benefit analysis favors high-traffic enterprises. You’ll see lower transit costs and better control over your routing paths. This approach follows the Core Principles of Modern Data Center Network Infrastructure Design by prioritizing path efficiency and resource optimization.
Building a Carrier-Neutral Strategy
True redundancy requires more than just two service contracts. You need diverse fiber paths that enter the building through separate conduits. If both carriers share the same entry point, a single construction accident can take your entire network offline. Designing for diversity ensures that a physical break in one path doesn’t impact the other. For enterprises with high security or compliance needs, private suites offer the ideal environment for dedicated carrier termination points. This setup gives you total control over your cabling standards and the physical security of your external handoffs.
Future-Proofing with Software-Defined Networking (SDN)
Decoupling the control plane from the data plane is the cornerstone of modern data center network infrastructure design. This separation allows you to manage the entire network fabric from a centralized controller rather than logging into individual switches to push manual configuration changes. You define policies at the software level, and the controller handles the distribution across the physical hardware. This approach is essential for handling the dynamic traffic spikes and unpredictable “east-west” flows that define AI-centric workloads in 2026.
Automation through APIs is no longer a luxury. By treating your network as code, you can provision resources in real-time to match application demands. This agility is supported by Network Function Virtualization (NFV), which replaces physical firewalls and load balancers with virtual instances. Reducing your physical hardware footprint not only saves valuable rack space but also simplifies your power and cooling requirements. It’s a more efficient way to manage a high-density environment while maintaining the technical stability your enterprise requires.
Security must be integrated into the foundation through a Zero Trust Architecture. SDN facilitates this by enabling micro-segmentation at scale. You can isolate specific GPU clusters or sensitive databases with granular policies that verify every connection, regardless of where it originates. This proactive stance ensures that security is a core component of your design rather than an add-on that creates performance bottlenecks. It gives you the peace of mind that your data remains protected even as your infrastructure grows.
The Benefits of an SDN-Ready Infrastructure
SDN-ready environments allow for rapid scaling. You can deploy new network segments almost instantly to support emerging AI projects or hybrid cloud expansions. Centralized monitoring provides improved visibility, letting you spot traffic anomalies or security threats before they escalate into outages. By automating configuration management, you significantly reduce the risk of human error, which remains a leading cause of downtime in traditional, manually managed networks. It’s about creating a system that is both fast and incredibly reliable.
Hybrid and Multi-Cloud Integration
Designing a unified network fabric ensures that your security policies remain consistent across on-premise hardware and public cloud environments. SDN bridges these gaps, creating a seamless experience for IT managers who need to move data between private suites and hyperscalers. SDN facilitates disaster recovery failover by automatically reconfiguring network paths and IP addresses to maintain service continuity during a site outage. This level of automation ensures your operations remain gondtalan (carefree) even during unexpected events.
If you’re ready to transition to a more agile and secure architecture, explore our managed data center solutions to see how we support modern software-defined environments.
Implementing Your Design: The Colocation Advantage
Designing a network blueprint is only half the battle; physical execution is where many enterprises face significant delays. Colocation providers accelerate your time-to-market by providing a ready-made environment with the power and cooling densities required for 2026 workloads. Instead of spending years on site selection and construction, you can deploy your data center network infrastructure design in a matter of weeks. This shift allows you to focus on logical configuration and application performance while the provider manages the facility’s technical stability and power delivery.
Physical layer maintenance is often the most time-consuming part of managing a distributed network. Utilizing remote hands support ensures that on-site experts are available to handle cabling, hardware swaps, and physical troubleshooting. This service acts as an extension of your own team. It allows you to maintain high uptime without the need to fly internal staff to the facility for routine tasks. It’s a cost-effective way to ensure your hardware remains operational and your connectivity stays fast in a high-density environment.
For enterprises requiring strict isolation and compliance, cage solutions provide a dedicated physical perimeter within the shared data center space. This adds a vital layer of security to your infrastructure, ensuring that only authorized personnel can access your specific racks. The ROI of this model is clear. You retain total logical control over your software-defined network while outsourcing the massive capital expenditure and operational burden of facility management. It’s about finding the balance between control and efficiency.
Scaling with Managed IT Support
Bridging the skills gap is a common challenge for growing enterprises. You can leverage the provider’s on-site technical expertise to manage moves, adds, and changes (MACs) efficiently. This eliminates the need to deploy internal staff for physical layer adjustments or rack reconfigurations. For a deeper look at operational best practices, consult our Remote Hands Support Guide. It details how to maximize efficiency and maintain high availability in a colocation environment.
Next Steps: From Blueprint to Rack
Begin with a comprehensive power and connectivity audit of your current infrastructure to identify immediate bottlenecks. Determine whether your design requires the density of a full cabinet or the privacy of a dedicated suite. Once your requirements are clear, the path from blueprint to rack becomes a streamlined and predictable process. Get a custom quote for your enterprise infrastructure design to start your deployment today and secure your place in the future of AI-driven architecture.
Building the Backbone for the Next Decade
The landscape of data center network infrastructure design has reached a critical turning point where efficiency and density are non-negotiable. You’ve seen how the transition to spine-leaf architectures and 1:1 oversubscription ratios is essential for supporting the massive “all-to-all” traffic patterns of AI clusters. Integrating carrier-neutral connectivity and software-defined automation isn’t just about speed; it’s about maintaining technical stability in an increasingly complex hybrid environment. By leveraging colocation, you gain the advantage of high-density facilities without the capital burden of building from scratch.
Success in 2026 depends on a foundation that’s high-density GPU ready and supported by expert technical oversight. Whether you’re optimizing for latency or scaling for global reach, the right partnership ensures your processes remain in expert hands. We provide the carrier-neutral connectivity and 24/7 remote hands support needed to keep your systems running at peak performance. It’s time to move from the drawing board to a live, scalable environment.
Design your future-proof infrastructure with 3EX Hosting and start building a network that grows with your enterprise.
Frequently Asked Questions
What is the best network topology for a modern data center?
Spine-Leaf is currently the gold standard for modern facilities because it provides predictable latency and high bandwidth for East-West traffic. This two-tier architecture ensures that every leaf switch is exactly one hop away from every other leaf. For extreme scale AI clusters, some enterprises utilize Fat-Tree or Clos networks to provide the massive, non-blocking throughput required for parallel processing.
How does Spine-Leaf architecture differ from traditional Three-Tier design?
Spine-Leaf collapses the core and aggregation layers into a single spine layer, which eliminates the bottlenecks found in legacy architectures. Traditional Three-Tier designs were built for North-South traffic and often suffer from congestion when servers need to communicate directly with each other. The Spine-Leaf model simplifies the path, ensuring consistent performance across the entire network fabric.
What are the networking requirements for high-density AI clusters?
High-density AI clusters require ultra-low latency and non-blocking fabrics with 1:1 oversubscription ratios. They often utilize specialized interconnects like InfiniBand or RoCE to manage massive, bursty data transfers during model training. Because these clusters often exceed 40 kW per rack, your data center network infrastructure design must also account for advanced cooling integration to maintain hardware stability.
Why is carrier neutrality important in data center network design?
Carrier neutrality prevents vendor lock-in and allows you to choose the best-performing Tier-1 providers for your specific geographic needs. It enhances technical stability by providing access to diverse fiber paths and competitive pricing within a single facility. This flexibility ensures that your external connectivity can scale or change without requiring a complete physical relocation of your hardware.
How do cross-connects improve network performance for enterprise applications?
Cross-connects eliminate the latency and unpredictability of the public internet by creating direct physical links between your equipment and a carrier. This bypasses multiple network hops and provides guaranteed, consistent throughput for sensitive applications. It’s the most efficient way to secure high-speed data transfers between your private infrastructure and critical cloud on-ramps or partner networks.
What is the role of SDN in data center infrastructure?
Software-Defined Networking (SDN) centralizes control and automates resource provisioning by separating the control plane from the data plane. It allows you to manage your entire network fabric through code, enabling rapid scaling and granular micro-segmentation. This approach reduces human error during configuration changes and provides deep visibility into traffic patterns across your entire enterprise architecture.
How can I future-proof my data center network for 400G/800G speeds?
Future-proofing requires deploying high-density fiber cabling and switches that support the latest IEEE 802.3dj standards. You should design for modularity so you can add capacity in predictable increments without replacing your core fabric. It’s also vital to ensure your physical environment can handle the increased power and cooling demands that come with next-generation 800G networking hardware.
Is InfiniBand or Ethernet better for AI-driven network designs?
InfiniBand is technically superior for large-scale AI training due to its credit-based flow control and native RDMA support, which minimizes CPU overhead. However, Ethernet with RoCE is often more cost-effective and easier for teams with standard networking expertise to manage. The choice depends on whether your priority is absolute performance for massive clusters or ease of integration with existing systems.